May '23: Moonfire, Part II
A bumper month: a new fund announcement, Moonfire Pulse 2023 preparations and the (r)evolution of our tech stack.


Hello and welcome to the May newsletter. It’s been a bumper month.
Last week, we announced our $115m raise to support and scale Europe’s best startups from the earliest stages, and to continue our mission to create a new type of venture.
We got a great response from the community and beyond. Here’s our pick of the coverage:
- Fortune: Can an A.I. algorithm spot the next Facebook or Uber? The founder of this European VC firm thinks so
- Reuters: Moonfire Ventures raises $115 million to fund European tech startups and AI firms
- Sifted: Data-driven early-stage VC Moonfire raises two new funds
We’re also busy prepping for Moonfire Pulse 2023, our signature founder and tech showcase event, on Wednesday 14th June. It brings together some of the most influential operators, investors and founders in European tech and venture to talk about the trends playing out in the ecosystem. Can AI transform healthcare? What’s the big European opportunity for LPs? Why is now the time to build in fintech? Look forward to seeing many of you there as we explore these topics. Should be a great day.
And for this month’s feature piece, Mike journeys through deep learning’s influence on AI and venture capital, looking through the lens of our own tech stack.
Enjoy.
Mattias and the Moonfire team
🌓🔥
What's Up at Moonfire?
Transformers, LLMs, and the (r)evolution of the Moonfire tech stack
This piece originally appeared in Andre Retterath’s Data-driven VC newsletter.
In this article, we delve into the journey of deep learning and its impact on the landscape of artificial intelligence (AI), with a specific focus on the venture capital sector. We'll explore the evolution of transformer models, such as GPT-4, that have become pivotal in today's state-of-the-art AI.
Through the lens of our technology stack here at Moonfire, we'll examine how these innovations are streamlining processes and aiding decision-making in venture capital. This article serves as an exploration of where we are, how we got here, and the potential direction of AI in venture capital, offering a pragmatic glimpse into an evolving future.
Transformers
The “state-of-the-art” (SOTA) in AI has shifted and evolved over the course of history. Deep learning-based approaches (neural approaches) to AI first became dominant in vision. When the convolutional neural network AlexNet was released in 2012, it not only popularised deep learning in computer vision, which dominated the domain for years, but sparked a deep learning revolution.
Then came ‘Attention is All you Need’ – the famous, and aptly named, 2017 paper that introduced the transformer model to the world. This model enabled the training of state-of-the-art models for language tasks, like translation and summarisation, without needing sequential data processing. All the powerhouse models today – GPT-4, BERT, PaLM – are transformers, using the same architecture but trained in different ways to do different things.
And that’s set us off on this crazy trajectory. I got really excited about transformers quite early on and ever since then I’ve been using them to play around with professional data like people, companies, learning content, etc. Transformers are really good at analysing language, and there’s a lot of language in professional data. I worked on this problem space of deep learning for natural language applied to the professional domain at Workday and I got a feel for how powerful these models were for dealing with this sort of thing. At Moonfire, I wanted to take this tech and apply it to VC.
My colleague Jonas and I have already written about how we’re using text embeddings at Moonfire to find companies and founders that align with our investment thesis, but we’ve been consistently working towards a grander vision for where we want to take AI in venture.
For the first two and half years at Moonfire, we basically partitioned the venture process into all of its various components, like sourcing, screening, company evaluation, founder evaluation, portfolio simulation, and portfolio support. Given that decomposition of the problem-space, we then built transformer-based models to focus on the specific tasks within that ecosystem.
We’ve gotten pretty good at that! But then GPT-4 came along. We were already using GPT-3.5, but GPT-4 was a step change. You can ask it a question and the output is often better than a smaller model trained for that specific task.
GPT-4 was a significant leap in performance
For example, we have one small model in our infrastructure called the venture scale classifier, which aims to answer the question, ‘is this company a venture-scale business?’ So is it a business that is venture investable from the perspective of growth, type of business, and stuff like that. It’s a subtle problem and it’s challenging to get a lot of useful training data. But it’s an important model for us, because it’s where we filter out a lot of the noise early on. So, if we can make iterative improvements to this model, it has a meaningful effect.
Jonas spent a quarter working on this model, before GPT-4, and improved it by 5%, which was incredible. Then GPT-4 comes out, he spends an afternoon with it, and gets a 20% improvement on top of that. We decided then and there that a critical objective for us would be to go through the whole stack and to try that for every model.
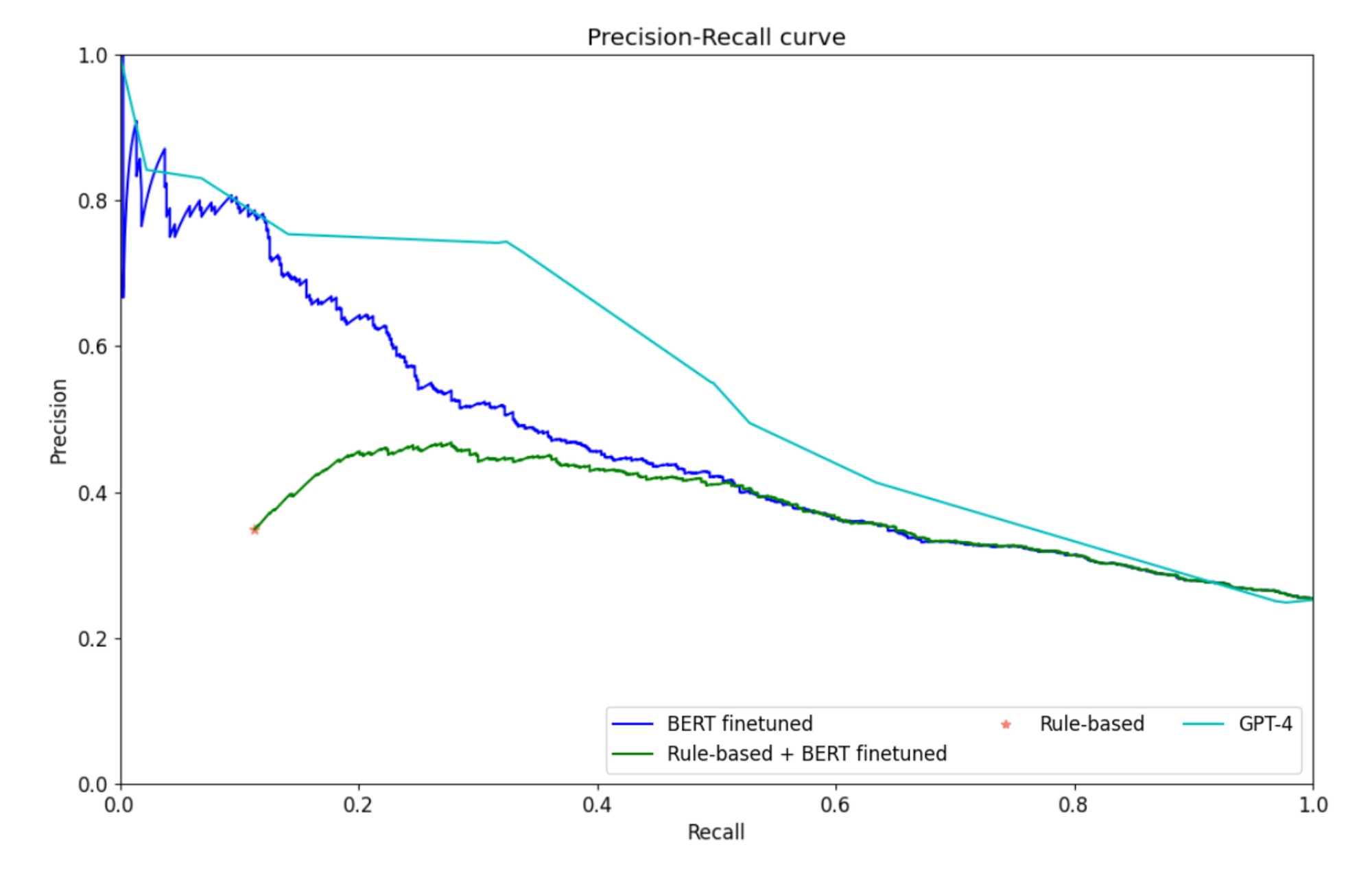
So that’s a bit of what we’ve been doing for the past few months. Around 75% of the time it’s better, but where we’ve trained a really optimised model for a specific task, the foundation model doesn’t provide an improvement. Not yet, anyway.
But we don’t want to just use LLMs to help us improve the individual parts. The idea is to create an architecture that allows us to integrate increasingly more powerful AI models into our infrastructure in a sustainable way: as they get better, we get better. We don’t want the way we’ve traditionally partitioned the space to become a straitjacket. We’re trying to think about it holistically – ‘what is the GPT-4 way of reasoning about partitioning the venture evaluation process as effectively as possible?’ That way, we’re not just bolting on AI, we’re completely reformulating the whole stack.
The ultimate goal is an end-to-end model where you just have one neural network doing basically everything; a future where software can write and improve itself, and where humans act more as supervisors and trainers of the AI. But that’s a way off yet.
The “10x VC” experience
So what does it look like for our investors? To start with, our pipeline was very investor-driven with some elements of automation. But we’ve been transitioning towards a more machine-driven process while allowing for a more focused investor perspective.
Currently it’s like a symphony between machine automation and our investors, working together to move the pipeline forward. We do a lot of automated and ML-powered sourcing and evaluation work, which outputs a few dozen companies each week for our investors to look at.
Then we’ve got a lot of infrastructure that automates this board of investment opportunities. So our investors interact with the pipeline through carefully designed interfaces that provide them with all the necessary information about a company, most of which is automatically populated by our AI and data infrastructure. Based on this information, they can make a more informed decision faster, whether it’s rejecting the company, following up, or making an investment.
Each investor's decision is a valuable learning opportunity for us. We get so little training data, so investors making actual decisions is the best training data possible for our models. We try to keep as much of that as possible.
Looking way ahead, I think we’ll see AI making the bulk of decisions, only requiring investor input for particularly complex issues – basically the stuff where humans are a better judge. So it’ll be like a handful of really focused interfaces that allow investors to make key decisions efficiently.
And now we’re thinking about how to increase the throughput of that decision making. It’s this iterative process of trying to learn as much as we can about our investors’ perspective and using that knowledge to guide them through the evaluation and investment process so they can focus on all the other decisions they have to make. Ideally, our investors will primarily focus on thesis inquiry, meeting high-quality founders, and making investment decisions.
Another firm might eschew human input entirely, and just try to build a fully automated pipeline. But our philosophy is: we hire top-tier investors and build the best ML and AI infrastructure, aiming to learn and integrate the perspectives of all our investors in a way that is really additive.
Every investor contributes significantly to our investment thesis and training data – even if we hired someone who only makes a few decisions before leaving. Collectively, everyone is making our engine smarter.
Orchestrating venture with agents
LangChain, a software development kit (SDK) designed to help developers use LLMs, says the following on their Python documentation:
We believe that the most powerful and differentiated applications will not only call out to a language model, but will also be:
1. Data-aware: connect a language model to other sources of data
2. Agentic: allow a language model to interact with its environment
How imperative is it for businesses to adopt this new way of thinking about technology and capabilities? LangChain and alternatives to it (HuggingFace’s Transformer Agent, Microsoft’s Guidance, etc) serve as a bridge between the language model and specific data sources or capabilities, providing the LLM access to structured information, APIs, and other data outside its original training set. By using these tools, developers can extend the functionality of an LLM, customising it to accomplish specific objectives, such as solving complex problems, answering specialised queries, or interacting with external systems in a more intelligent and context-aware manner.
The idea of data-awareness amplifies the capabilities of language models, enabling them to connect and interact with a broad spectrum of data sources, thereby providing more relevant, accurate, and insightful responses. This is particularly useful for tasks like investment research, founder evaluation, and company evaluation; all of which require a comprehensive understanding of a variety of data points.
Similarly, allowing language models to interact with their environment, or being agentic, pushes the boundaries of their potential applications. It enables them to engage in real-time data exchange with various systems, make decisions based on current context, and even execute actions, greatly enhancing automation capabilities.
Multiple perspectives in an agent-based world
While some firms intentionally cultivate adversarial perspectives, our goal is to unify these viewpoints – and this is feeding into our own discussions as we develop AI agents or digital investors! Should we have separate agents for each investor to account for the fact they each have their own biases, priorities and ways of thinking about things? Or could we employ a single agent capable of weighing these different perspectives and tweaking its approach though prompting?
I think the latter works in the context of one firm, but we will see some really interesting stuff when the AI agents of different companies, different people start interacting with each other, because they’ll have to collaborate and negotiate. Perhaps that is how companies will interact in future, like a core communication fabric. But that moment will be the beginning of an exponential explosion of agents – all coordinating and competing for things. That’s for another blog post.
Despite being only a few years deep into using transformers in the venture stack, it’s already clear that this marks a significant shift in how we, and the venture world at large, operate. We wrote a piece recently discussing the concept of the 10x VC, where AI makes VCs much more efficient. I think it’s more on the scale of n^(10)x, as machine learning has the capacity to exponentially enhance our capabilities. That’s what we’re shooting for.
The n^(10)x VC?
The ongoing evolution in AI, led by transformer models like GPT-4, has ushered in a transformative era across various industries, particularly in venture capital.
Our pioneering approach to integrating AI into venture processes showcases some of the gains in efficiency and decision-making accuracy this new perspective brings.
By embracing the data-aware and agentic potential of LLMs, VCs stand to gain unprecedented capabilities in handling complex problems and streamlining operations. In the VC landscape, these advancements empower investors to focus more on high-level decision-making tasks, amplifying their effectiveness in building relationships with founders and spotting the next big venture-scale business.
As we gaze into the future, the possibilities for AI, and specifically LLMs, seem boundless. The prospect of AI agents communicating and collaborating with one another across different platforms and firms hints at a paradigm shift in all businesses, but also venture investing, heralding an exciting future that could redefine the venture capital landscape.
In my opinion, the path forward is to embrace these innovations and continuously seek ways to better harness their potential, always striving for that n^(10)x efficiency that this new AI era promises.
– Mike 🌓🔥
Podcast of the Month
Lex Fridman Podcast: #333 – Andrej Karpathy: Tesla AI, Self-Driving, Optimus, Aliens, and AGI
An oldie but a goodie. Andrej Karpathy, computer scientist at OpenAI and previously director of artificial intelligence and Autopilot Vision at Tesla, is one of the clearest, and most prescient, thinkers on this new wave of AI. This broad-ranging discussion captures a lot of his thinking.
Also worth checking out his excellent Software 2.0 piece. This was written all the way back in 2017 (ancient history in AI terms), but it’s remarkable what he got right about the way AI is now developing. His thesis is that AI is a new and powerful way to programme computers.
Good Read of the Month
Transformer: The Deep Chemistry of Life and Death by Nick Lane
More transformers – but this time the biological kind.
We recommended British biochemist Nick Lane’s earlier book, The Vital Question, in January’s newsletter. In this latest book, he focuses on the Krebs cycle, part of the metabolic pathway that releases stored energy our cells can use. He argues that it underpins everything from the beginnings of life (because the basic chemistry of the Krebs cycle occurs spontaneously), the birth of biological information (the ‘letters’ of DNA), cancer and age-related diseases – all the way to consciousness.
It covers some similar ground to The Vital Question, but delves further into the details and brings in more recent research. And the focus on the energetic and electrical foundations of life makes for a refreshing change from the informational, DNA-centric perspective that has dominated biology for the last couple of decades. Really interesting read.
That’s all for this month. Really excited for the next stage of Moonfire’s journey with Fund II, and looking forward to seeing many of you at Moonfire Pulse 2023!
Until next time, all the best,
Mattias and the Moonfire team
🌓🔥