Moonshot II: Artificial Chemistry
In the second edition of our AI newsletter, we talk to Victor Schmidt, CTO of AI-driven materials discovery startup Entalpic, alongside a roundup of recent developments, and what we've been thinking about and working on.




Welcome to the second edition of our AI newsletter: Moonshot.
This time, we’ve got an interview with Victor Schmidt, Co-founder and CTO of Entalpic, a generative AI platform for discovering new chemicals and materials for carbon intensive industries, and a long-time friend of ours.
He and Jonas discuss why he chose to start his AI company in Europe, what he’s most excited about in the space, and his advice for PhDs thinking about starting a company.
We’ve also got our usual roundup of the latest developments, and what we’ve been thinking about and working on recently.
– The Moonfire engineering team: Mike, Jonas, and Tom 🌗🔥
Interview with Victor Schmidt
Co-founder & CTO of Entalpic

Here are some of the highlights from our conversation.
How are you connected to Moonfire?
My first encounter with Moonfire was in 2016. Moonfire didn’t exist then, but Jonas Vetterle did. We met while studying together in UCL’s MSc Machine Learning program and stayed close friends over time and distance.
A few years later, during my PhD with Yoshua Bengio at Mila, I met Mike, who joined our climate change visualisation project. He helped industrialise and improve the UX/UI of the app that we had started, and we’ve stayed in touch ever since.
But it wasn’t until later that I realised that you were both working together. When two cool people come together in such a small team, it’s worth paying attention!
To the extent that you can, explain what you’re building at Entalpic.
Entalpic is an AI-driven materials discovery company, fostering greener and smarter industrial processes. What we really want to do is to explore the space of potential materials, catalysts in particular, that can drive and improve chemical reactions.
“Improve” can mean being more selective with what materials you use, eliminating rare earth or scarce materials from processes, improving the reaction rate, or reducing the amount of energy that you need for a reaction to happen – all valuable for industrial applications.
Our focus is chemical reactions that 1) make business sense, 2) have scope for eliminating environmental risk, and 3) work from an AI perspective – so it’s in a design space where we can compute things. That’s where we’re going to find the most impactful partnerships.
You decided to move back and start your company in France. What are the strong points of the European startup ecosystem? Anything particular about France?
First, it’s in Europe, so there’s a lot of opportunities for international collaboration, facilitated by the EU. The ease of hiring across countries, like bringing in talent from Germany or wherever, for example, gives you easy access to a large, diverse pool of talent.
Second, France has a good support system for startups, and a strong deep tech ecosystem. A lot of public funds are available, so it's not uncommon to add 50 to 100% in public funds to your private funding.
It’s also really easy for us to just hop on a train from Paris to visit potential industrial or academic partners across Europe. That has a lot of value for us.
I also felt like being involved in my home country, and contributing to the strengthening of the AI scene in Europe.
What's the role of open source in AI, and who will win – closed or open source?
Open source has been one of the most important drivers of the development of AI in the past few years, starting with Theano out of Mila over a decade ago, and Caffe and Caffe2. TensorFlow, Keras, PyTorch, and more specialised libraries like Hugging Face Transformers, all open source, have help drive AI forward.
Open source has also made knowledge more accessible. We're lucky to have a community with an open-source and open science tradition. You rarely have to pay to access a bit of research or a paper, making it easy to learn at very different levels of complexity. You can read a high-level blog post about something pretty complex to get a rough idea, and then either move on or dig deeper. That fine-grained access to complexity is absolutely unique.
Now, whether open source or closed source will win, that's a very different question. It depends how you factor in the issue of safety.
If we think of AI as just another technology, and set aside the issue of safety, I don't think either will win – they’ll coexist. There are plenty of open-source models and open-source business models where you can have something that’s open and accessible. But if you want more performance, if you want support, if you want customisation, that's something you have to pay for.
The question of safety is more complex, and I don't have a strong opinion. I understand the risks, and there are multiple levels to them, but it’s often framed in a binary way – either ignoring risks or focusing only on existential threats. I see it as a spectrum. As a society, we need people who care about existential risks in the long term and more immediate, pragmatic risks in the short term.
We need to mitigate bias, use AI ethically, and be mindful of the climate impact of AI – from resource extraction to produce the hardware that we use, to energy consumption. For example, I'm not sure using LLMs to query something that we can get from Google is a very good way forward in terms of the ratio of energy that's used.
To connect back to open vs closed source, I’m not sure. We need processes at the scale of our society to address it. We can't think about it from a purely technical perspective.
LLMs are getting so much attention right now, in academia, among founders, investors and the general public. How did this affect you during your PhD or now as a startup founder?
For founders, whether or not your startup focuses on LLMs or AI, you have to live with the hype. Investors expect that there will be LLMs somewhere, somehow. But there are also truly transformative ways in which you can use LLMs, like their ability to aggregate and synthesise knowledge. While not perfect, their capacity to process vast amounts of content will change how we do science, including in industry.
So I think LLMs will be transformative – but they’re not the answer to everything. They have some potentially intrinsic limitations when it comes to science. For example, they're not able to handle numbers well yet. But I'm not a fatalist; I don't think there are fundamental restrictions. We just haven’t found the right approach yet, and maybe we won’t, but I don’t see an intrinsic impossibility there.
What's the most exciting thing for you in AI? And maybe you can tie it into your thoughts on the current state of AI model architectures. Do you see Transformers continuing to dominate, or are there any promising alternatives on the horizon?
In the past two or three years, the rise of AI for sciences has been really exciting. Being able to use AI to advance other fields and investigate scientific processes is something I really appreciate. AI is not just evolving in a bubble – it’s connecting other sciences up in new ways and making those connections mainstream.
There have always been people working on physics for neural networks or neural networks for physics and whatever comes in the middle of those two things, but now it's becoming much more mainstream. It's being driven, in part, by the interest from the pharma and life sciences industries in generative models and the search abilities of AI. Active learning, Bayesian optimisations… those things are becoming more trendy or visible in AI conferences. I was at ICML (International Conference of Machine Learning) earlier in July, and I have never seen so many applied science papers. So I think that's pretty exciting.
As for Transformers, I don't have a strong opinion. Technologies evolve and get replaced, and I trust the ability of the human mind to come up with new solutions. Transformers reflect an era of abundant data in vision and text, where people were like, "Oh, maybe if you have more data, more compute, then we don't need the inductive biases anymore." But in many AI applications, especially in science, we don’t have that much data, so you need inductive biases to learn effectively from a smaller amount of data.
I do think there will be alternatives to Transformers for specific use cases. They may not be as ubiquitous as Transformers are today, but they don’t need to be. For example, xLSTMs seem to be pretty efficient in handling sequences, and you can use a Graph Neural Network architecture to handle atoms in space. Transformers might remain the dominant architectures, but I don’t think the evolution stops there.
Do you have any advice for people finishing their PhD, thinking about starting a company?
First, having a scientific background and an idea or technology isn't enough. You need to go beyond that, whether by joining an accelerator or incubation programme.
Don’t underestimate the need for a CEO. A product-oriented vision, understanding the needs of users, and grasping the structure of a market are just as important as the technology you're developing. And it's not something that should wait – they should be part of your company as early as possible. Having a business co-founder, preferably someone who's also got experience in the area you’re tackling, is paramount.
But finding someone you trust with your life almost, someone that is as involved and committed to the project, who believes in it as much as you do, is difficult. It's better to be patient and wait to find the right person than to start with the wrong person. Programmes like Entrepreneur First can help you with this.
Another thing is just getting out there, talking to people and building your network. It's unlikely someone will steal your idea – and, if they can, maybe it's not a great idea. A lot of the success of a company lies in the execution, your vision, and how you do things, not just what you're doing. I don't think being too secretive about what you're doing is very helpful, especially if you're new to this world. Go out there, get your idea challenged. For us, the process of fundraising taught us a lot about our ideas and about building this company.
So just put yourself out there and contact people. The worst they can do is not reply, but most people will be willing to spend 20 or 30 minutes with you discussing what they’re passionate about.
Read more about Entalpic and its €8.5m Seed round.
What's been happening
It’s been a busy time for open source AI. Mistral released its new flagship model, Mistral Large 2, Meta came out with Llama 3.1, Apple with DCLM 7B, and Groq launched two models specifically designed for tool use. Just to name a few.
Amongst the team, Claude 3.5 Sonnet has become our (or Jonas’s, at least) go-to chatbot, although GPT-4o still performs better in our internal benchmarks. We’re excited for the release of Opus 3.5 to see how it stacks up.
On a smaller scale, GPT-4o-mini, the replacement for GPT-3.5-turbo has really impressed us with its results, considering its size.
OpenAI and Google now also offer fine-tuning capabilities, which we’ve started using (more on that below).
Beyond models, we’re also excited by rapidly increasing context windows – Google’s Gemini models come with a whopping 2M token count, batch predictions and prompt caching. The latter two lead to dramatic cost reductions!
In terms of new papers, one standout is TextGrad, from the Stanford NLP lab, which allows for fine-tuning of prompts using a PyTorch-like syntax, essentially automating the process of prompt engineering. That makes it ideal for working with closed-source models where you can’t modify the model parameters. So instead of fine-tuning model parameters (which you can’t do anyway with closed source models) on a specific task, you fine-tune the prompt on the specific task.
We’ve also been interested in the “What’s the Magic Word? A Control Theory of LLM Prompting” paper. As the authors say, prompt engineering has a bad reputation as a heuristic field, but we’ve barely scratched the surface of what can be done with it. The paper shows how significantly even short prompts can influence LLM outputs – and the space of possible token sequences used as prompts is vast. This paper reframes prompt engineering as a scientific problem to better understand it and, ultimately, improve our control of AI models. Here’s a good podcast with the authors.
What we're thinking
We’re at a pivotal moment where open-source models are rapidly catching up with closed source.
We love Meta’s open source approach to LLMs. It’s great news both for startups and academia, and it’s a big move for Meta: establishing itself as the platform for AI products, helping it attract and retain the best AI talent, challenge competitors, and foster innovation – all by releasing open source models at a relatively low cost (considering Meta’s scale).
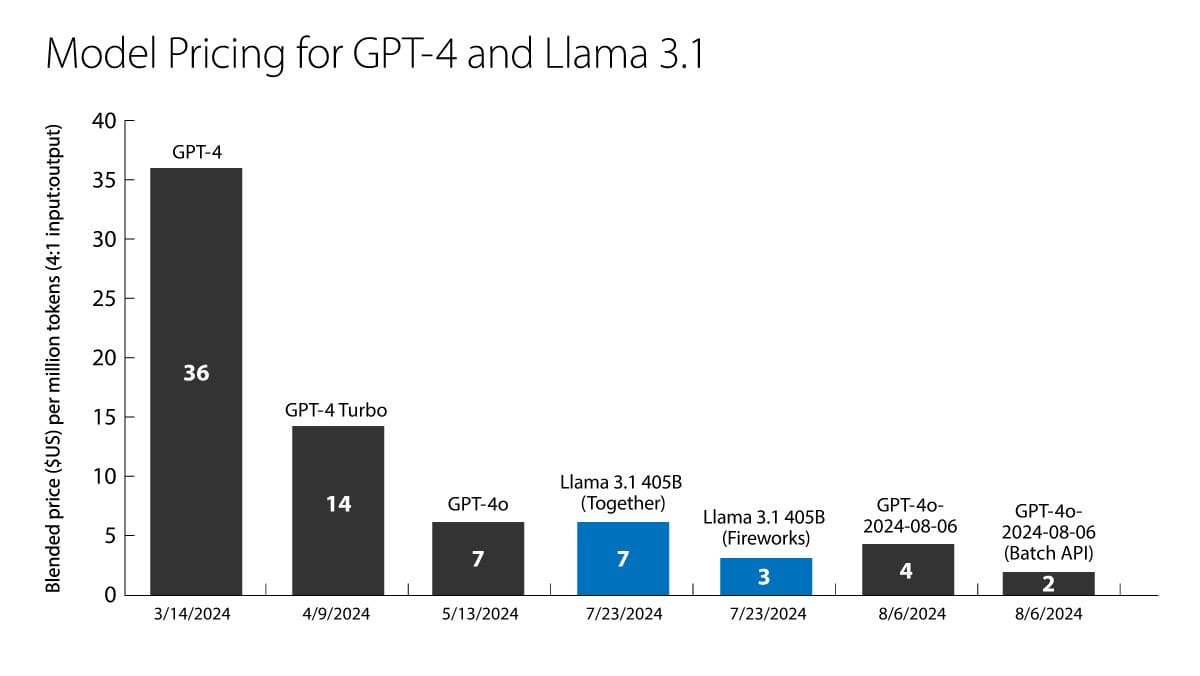
So far, everything’s going as expected. New, better, multi-modal models are coming out, prices are coming down (GPT4o-mini is 80-90% cheaper than GPT3.5-turbo), and open-source models are not only catching up with but in some cases, surpassing their proprietary counterparts.
There are a couple of clouds.
The regulatory environment in the EU is concerning, for both builders and consumers. Meta recently announced that it won’t release its multimodal Llama model in the EU due to regulatory uncertainty, and Apple is similarly withholding Apple Intelligence. This restrictive approach and general antagonism towards US companies could slow the pace of AI innovation and adoption in Europe.
There’s also a shift in sentiment – some are beginning to wonder if we’re in an AI bubble. Part of the euphoria is probably down to the fact that it’s relatively easy to get to 80% performance – but pushing beyond that to 90% or close to 100% is where the real challenge lies.
But we’re not concerned. Startups are in build mode and markets are waiting for the real value creation.
The jump from GPT-3 to GPT-4 was a huge step change in performance. Improvements have been more incremental since then, but we’ll see if GPT-5 and Llama 4 bring another breakthrough or if we’ve reached a plateau in foundational model performance.
Our advice is to filter out the noise, focus on building, and aim to create model-agnostic products that get better as foundation models get better.
What we've been up to
We’ve been getting our hands dirty with TextGrad, and continuing to push the performance of our internal AI workloads.
We’ve also been running a few experiments to see if we can fine-tune an LLM to improve one of our RAG-based workflows. We set out to answer:
- Can we somehow fine-tune an LLM on our corpus in order to improve the performance of our RAG pipeline?
- Is it possible to fine-tune a less capable LLM such that it matches the performance of a more capable LLM?
We’ll publish a piece on our findings soon. Stay tuned!
Until next time, all the best,
– Mike, Jonas, and Tom 🌗🔥