An introductory reading list on AI for Scientific Discovery
Exploring the potential of AI-driven science – and the new machine learning frameworks that might help us get there.


‘We want AI agents that can discover like we can, not which contain what we have discovered. Building in our discoveries only makes it harder to see how the discovering process can be done.’ – Rich Sutton, The Bitter Lesson
The largest potential impact of artificial intelligence lies in its ability to accelerate scientific discovery and rewrite how science is done. I don’t think it’s hyperbole it to say that this would be one of the great defining moments of human history – the next scientific revolution – spoken in the same breath as the microscope, the research lab, and the computer.
AI has already made tremendous progress in recent years. It has enabled breakthrough advances in protein folding prediction, identified new antibiotics, controlled plasma in nuclear fusion reactions, and allowed the prediction of the next week of weather 45,000 times faster and more accurately than current forecasting methods.
But I hope that it will also transform the way science is done: automated literature reviews and hypothesis generation, faster and cheaper reproduction of others’ results, and eventually the development of self-driving labs – already emerging at companies like Emerald Cloud Lab and Artificial.
As an engineer trying to reimagine venture capital with AI at its core, this transformation is instructive. Like much modern work, the work of science involves a lot of manual, time-consuming intellectual labour. The challenges AI seeks to address in science mirror those in various industries, underscoring its potential to reshape the future of work for all of us.
But applying AI to scientific discovery is an especially hard problem. Current foundation models can struggle with highly specialised domains, and more specialised models aren’t that good at generalising beyond their training data, making it harder to more broadly apply them to the practice of science. Different intellectual objectives require models with different kinds of abilities. In the best scientific tradition, only experimentation by researchers and practitioners will find out what works. And there’s a lot of cool work being done to figure it out.
Below are a few papers and resources I’ve found interesting in thinking about AI in science and where it’s going. This is by no means exhaustive, and there’s a bias towards Professor Yoshua Bengio’s work on generative flow networks (GFlowNets), because that’s what I’ve been thinking about recently and I really appreciate the way that he approaches this problem. I would love to hear what you’ve been reading in this space!
Better reasoning machines
Scaling in the service of reasoning & model-based ML. This blog post by Professor Bengio and Edward Hu argues that both scale and human-like inductive biases are needed to create more effective models. Professor Bengio’s work focuses on the gap between current machine learning and human intelligence, trying to find where human inductive biases can be usefully applied to machine learning to make it more effective at certain types of intellectual tasks.
To reason well, they argue, you need to have 1) a good model of the world and 2) a powerful inference machine capable of generating solutions that align with that world model.
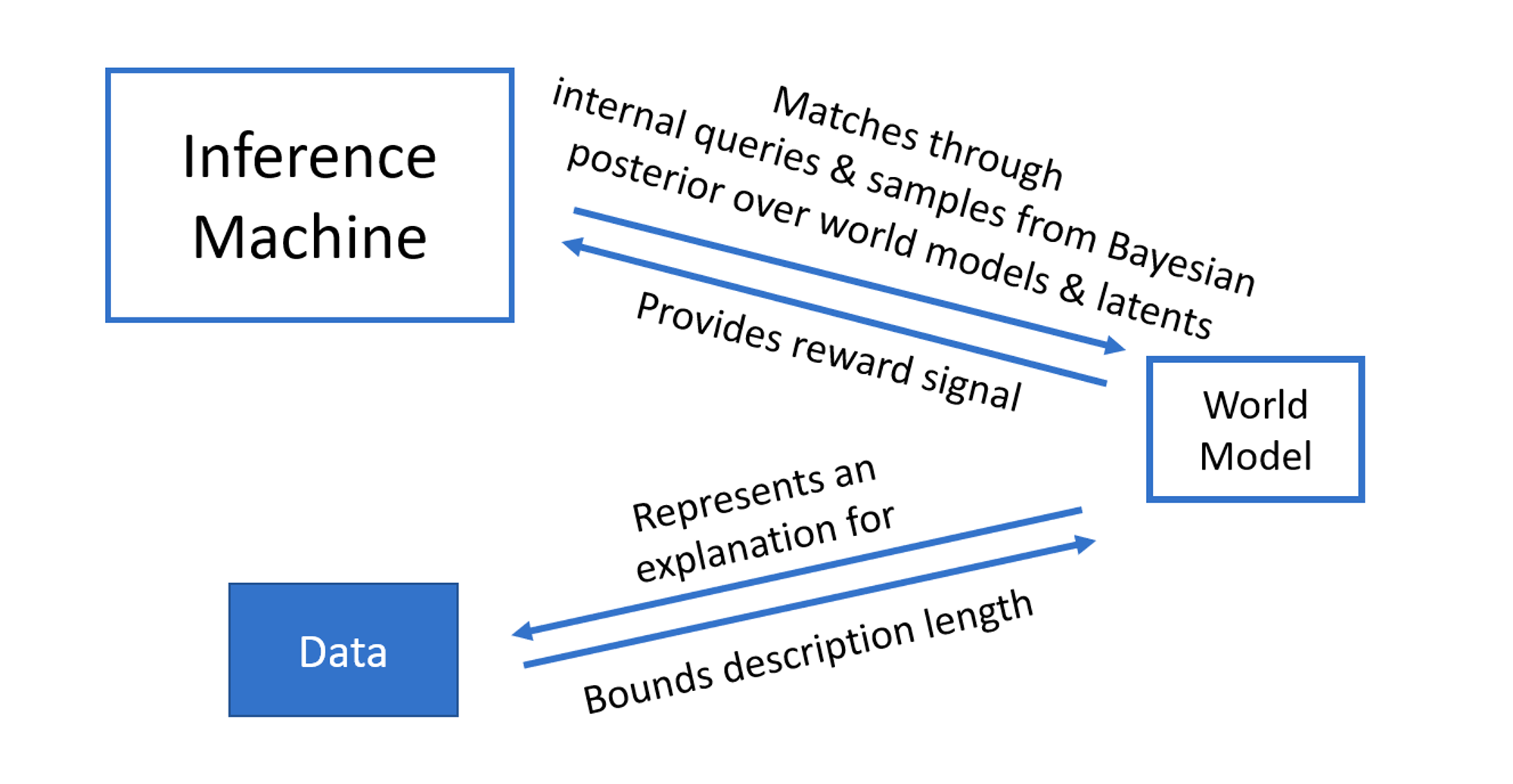
The problem with current ML models, they suggest, is that the world model and inference machine are one and the same; the world model it creates over-fits to its data, making it hard for the model to generalise to new observations.
They propose to separate the world model and the inference machine, but exploit modern deep learning to train a very large amortised inference machine. In simple terms, this means creating a machine that can “intuit” an answer with reference to the world model, in a similar way to how human intuition is based on heuristics that we accumulate, and can adapt, through experience.
They illustrate this through Daniel Kahneman’s famous distinction between two types of human thinking: System 1, characterised by fast and associative thinking, and System 2, characterised by slow and deliberate thinking. Current ML models can be likened to System 1 thinking, and only a future System 2 architecture will be able to handle robust reasoning. But, so they argue, a standalone System 2 neural network is not the answer. You need an inference machine that can make fast System 1 intuitions, with a System 2 organising the computation and training of the former to align with the world model.
Generative flow networks (GFlowNets) are a step towards this method.
GFlowNets
GFlowNets for AI-Driven Scientific Discovery. This paper is a good summary of the challenges that current ML faces in scientific discovery – and offers a way forward: generative flow networks, or GFlowNets. Sections 2 and 3 are great for a broad background of the space, and the citations contain a wealth of interesting history and perspective.
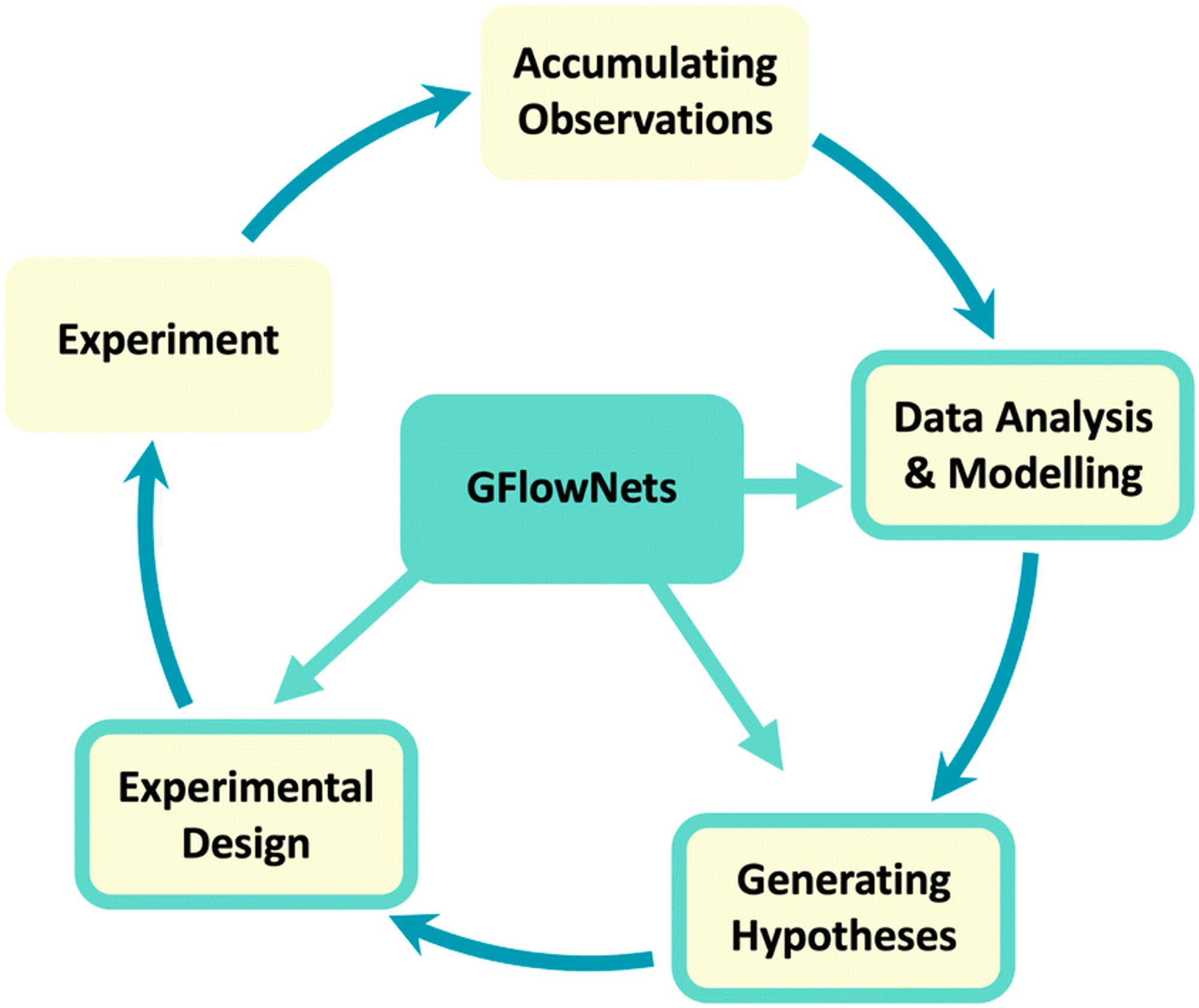
Recent advances in AI-driven science have been enabled, in part, by the availability of extremely large datasets and often of a well-specified objective to be optimised. But in many scientific discovery applications the 1) limited availability of data and the associated uncertainty, and 2) the underspecification of objectives pose serious challenges for leveraging ML approaches.
Usually, models are trained to maximise a given reward function, so they converge around one or a few high-reward samples. In contrast, a GFlowNet is trained to fully explore the sample space. Instead of minimising the loss or maximising rewards, it samples solutions proportionally to the reward, producing a wider variety of samples. In other words, instead of finding the result that gives you the largest reward, the model will try to find all the ways that get you good rewards.
If you were playing chess, a GFlowNet would be a bad fit: you want a model that finds and plays the best move, not diverse moves. But it is ideal if you are trying to solve a highly complex real-world problem of high uncertainty, like new material or drug discovery, where you want to keep your options open and test various promising candidates in the solution space, not just one.
These videos from Microsoft Research and Machine Learning Street Talk with Professor Bengio provide good overviews of the concept.
Democratised science
As well as new frameworks, AI-driven science will also be advanced by the democratisation of technology.
IBM has already released its Generative Toolkit for Scientific Discovery (GT4SD), an open-source library which makes GFlowNets – as well as various other state of the art models and frameworks – more accessible. What used to require a computer science PhD and lines of arcane programming languages can now be deployed through a simple interface and a few lines of code, accelerating hypothesis generation.
Or take one of the most important papers for AI-driven science: Highly accurate protein structure prediction with AlphaFold. (Here’s a great explainer for why AlphaFold 2 was so important.) This not only solved the protein structure prediction problem – a problem central to biology – but also made the codebase publicly available, allowing anyone with modest compute to run their own predictions. RoseTTaFold has done the same for characterising multiprotein complexes. They have opened up a world of new research paths for computational biology.
This is just the beginning of AI’s impact on scientific discovery, but it’s an exciting time to be alive and witnessing it – as both a human and an engineer trying to rethink my own field with AI.