AI is the new BI
The startups shaping the future of data and work with AI, automation, and low-code/no-code.



It’s often said that data is the new oil – valuable, abundant, and easy to store. Businesses build their data stacks and stockpile data without really knowing why they’re doing it or what they plan to do with it. But does that really matter?
AI’s capability, powered by vector search, to sift through unimaginable mounds of data and find – and generate – what you’re looking for is changing the way businesses approach their own data, infrastructure, and how they build data products for their customers. The key lies not in why or how the data was collected, but in having the data and properly orchestrating it.
If data is the new oil, then LLMs are the environmentally friendly fracking rigs, blasting value from unstructured text shale formations.
— Tomasz Tunguz (@ttunguz) July 12, 2023
The early stages of this are already playing out, with AI assistants being able to convert natural language prompts into SQL queries the user can then run, and the largest SaaS enterprises in the world releasing English language APIs. This new layer of abstraction allows data teams – and eventually anyone – to query data through natural language and other low-code approaches.
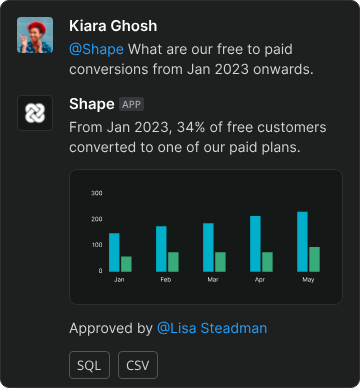
A host of startups are building in this space, each focusing on specific use cases and workflows, with a collective ambition to make data handling more intuitive for every individual, regardless of their technical background. Lightdash does exactly that, turning dbt projects into full-stack BI platforms where analysts can write metrics and the whole team can answer their own queries with no SQL needed. Latitude’s simple visual UI and AI assistant allows startups to explore, visualise, share, and collaborate on their data, without countless hours of dev time spent building and maintaining data pipelines. Shape automates ad-hoc data queries by allowing users to get AI-generated – and analyst approved – answers to data questions on Slack. And Calliper focuses on helping leaders at high-growth startups make faster, better decisions, with automated customer insights and alerts.
Next will come the GitHub Copilot for every kind of data practice – scaling capabilities with humans in the loop. Not just being able to query your data, but train on your analytics codebase to help navigate dbt and orchestrate your data models and pipelines more effectively. Startups are already building for that future. Dagster has created a cloud-native orchestrator for the whole development lifecycle – from local development and unit tests, all the way up to production – with integrated lineage and observability, a declarative programming model, and best-in-class testability. And Orchestra allows users to define, control and monitor their data pipelines through a no-code / low-code UI, further democratising and simplifying data orchestration and observability. Alongside, the data stack will have to evolve to become more AI-native, focusing on the optimal ways of pre-processing, embedding, retrieval, and inferencing.
Looking much further ahead, as models and controls improve, we will see more accessible, democratised business application development. Rather than ever-better BI visualisations to help direct business or product strategy, you ask the model how to solve a business problem and it advises on, and perhaps partially designs, the software and data models you need to do it. If you can imagine it, you can build it – if you have the data to power it and the constellation of models to handle it. As Beyond Work is setting out to do, it’s about using AI as the core engine for a new way of working, and eliminating a lot of the tedious labour that is in every digital job today along the way.
The edge at all these inflection points is data. And not just proprietary data. In an API-first world, data calls are easier than ever before, and the ability to amalgamate and probabilistically weigh external and synthetic data alongside your own will play a big role. A lot of perceived competence comes from the models themselves, but an extraordinary amount of untapped perceived competence will come from giving AI models access to the right data and allowing those models to take interesting actions.
Of course, in an increasingly interconnected digital world, businesses will need to think about what data they’re sharing, how data is being stored, and how models are being trained. Different levels of data sensitivity will necessitate a nuanced orchestration of both internal and external data and models. All rich earth for new startups to mine.
This latest AI wave has ripped up the playbook for product development in data and beyond. Where something like robotic process automation was built from the ground up, LLMs are top down – making them a lot more flexible in orchestrating and creating knowledge. It's a clean slate, an opportunity to take new approaches to data that shape the future of work. If you're a founder building in this space, we'd love to talk.